Introduction
Demonstrating e-commerce search requires a catalog with realistic titles, working images, usable categories and attributes, and sufficient product variety to observe the effect of query rewriting or re-ranking. In other words, the dataset needs to behave like a real catalog.
In practice, it can be surprisingly hard to find demo data that is (a) sufficiently large, (b) easy to ingest, and (c) safe to use in commercial settings. A common workaround is to use a smaller dataset, a synthetic catalog, or a source format that requires significant one-off parsing. That tends to make demos less convincing and reduces the likelihood that the same experience can be reproduced on real-world production catalogs.
For some query rewriting work I’m involved in, I needed an image-rich product catalog and a clean representation of that catalog that could be indexed and iterated on quickly. To support this, I built two tools that take data from open sources and output demo-ready NDJSON. One pipeline is based on Open Food Facts and produces over 100K usable grocery products; the other is based on Open Icecat and produces over 1 million usable computer/electronics products. These tools take data that often comes in awkward formats (nested JSON/XML, inconsistent field names, and image metadata that isn’t directly usable) and convert it into clean NDJSON documents with a consistent schema.
The harvesters
To produce demo datasets, I built two open-source transformation pipelines. These tools convert messy product records into clean Elasticsearc-ready NDJSON:
- Icecat Harvester: Downloads Icecat XML and normalizes electronics metadata.
- Open Food Facts Extractor: Parses Open Food Facts JSONL and extracts grocery attributes and images.
NDJSON
Elasticsearch ingests JSON documents. NDJSON is a file format that allows one JSON object per line, which is trivial to bulk ingest. The output of these harvesters is a clean, stable schema that can be bulk-ingested directly into a search engine.
Dataset #1: Open Food Facts as a demo catalog
Open Food Facts is not an “e-commerce” dataset in the Amazon sense. It is a product database built for transparency: ingredients, allergens, nutrition, and label-derived metadata. The reason it works well for demos is that it still behaves like a real product catalog: it has product names, categories, and images. Importantly, its data reuse posture is explicit and documented (ODbL for the database; CC BY-SA for images). That clarity matters when you intend to show a dataset to customers.
The raw Open Food Facts export is a large JSONL file with a lot of structure. The extractor repository turns it into clean NDJSON that is immediately indexable. It also computes image URLs based on the official image URL scheme, and it can apply quality gates such as “English titles/descriptions” and “must have a front image.”
Open Food Facts inclusion criteria
After parsing, filtering, and cleaning over 4.2 million source records from Open Food Facts, the resulting dataset contains over 100K clean JSON objects. This reduction is expected: the extractor is intentionally strict because the goal is a catalog suitable for demos.
A record is included only if it meets all of the following:
- English title and description
- A usable front image
- At least one meaningful category (placeholder/empty categories are excluded)
- A category hierarchy that resolves against the Open Food Facts taxonomy (products whose
category_pathcan’t be reconstructed are dropped by default, so every product is drill-down faceable)
This is intentional: for demos, incomplete products (missing images or categories) are usually not useful.
After: Cleaned NDJSON for grocery search
This resulting data is ready to be indexed into a search engine like Elasticsearch or OpenSearch, and looks as follows:
{
"id": "0008127000019",
"title": "Extra virgin olive oil",
"brand": "Athena Imports",
"description": "Extra virgin olive oil. Extra virgin olive oil Key specifications: Category: Plant based foods and beverages; Serving size: 15 ml; Nutri-Score: B; NOVA group: 2; Eco-Score: E; Dietary restrictions: vegan, vegetarian; Ingredients analysis: palm-oil-free, vegan, vegetarian; Energy (kcal/100g): 800 kcal; Fat (g/100g): 93.3 g; Saturated fat (g/100g): 13.3 g; Sugars (g/100g): 0 g; Salt (g/100g): 0 g; Protein (g/100g): 0 g; Countries: United States",
"image_url": "https://images.openfoodfacts.org/images/products/000/812/700/0019/front_en.5.400.jpg",
"price": 14.29,
"currency": "USD",
"categories": [
"Plant based foods and beverages",
"Plant based foods",
"Fats"
],
"category_path": [
"Plant-based foods and beverages",
"Plant-based foods and beverages/Fats",
"Plant-based foods and beverages/Fats/Vegetable fats",
"Plant-based foods and beverages/Fats/Vegetable fats/Olive oils",
"Plant-based foods and beverages/Fats/Vegetable fats/Olive oils/Extra-virgin olive oils"
],
"attrs": {
"Serving size": "15 ml",
"Nutri-Score": "B",
"NOVA group": "2",
"Eco-Score": "E",
"Ingredients analysis": "palm-oil-free, vegan, vegetarian",
"Countries": "United States",
"Category": "Plant based foods and beverages",
"Energy (kcal/100g)": "800 kcal",
"Fat (g/100g)": "93.3 g",
"Saturated fat (g/100g)": "13.3 g",
"Sugars (g/100g)": "0 g",
"Salt (g/100g)": "0 g",
"Protein (g/100g)": "0 g",
"Dietary restrictions": "vegan, vegetarian",
"Price source": "estimated_unit_model",
"Pricing bucket": "oils_fats",
"Estimated unit price": "11.59 USD/l (15ml, bucket=oils_fats, scale=1.21, ratio=0.15)"
},
"attr_keys": [
"Category",
"Countries",
"Dietary restrictions",
"Eco-Score",
"Energy (kcal/100g)",
"Estimated unit price",
"Fat (g/100g)",
"Ingredients analysis",
"NOVA group",
"Nutri-Score",
"Price source",
"Pricing bucket",
"Protein (g/100g)",
"Salt (g/100g)",
"Saturated fat (g/100g)",
"Serving size",
"Sugars (g/100g)"
],
"dietary_restrictions": [
"vegan",
"vegetarian"
]
}
Note: attrs["Dietary restrictions"] reflects the raw, display-friendly value, while dietary_restrictions is a normalized array for efficient filtering/faceting.
Reconstructing a real category hierarchy
A good e-commerce demo needs more than a flat bag of category labels — it needs a category tree you can drill into (Snacks → Salty snacks → Crisps). Open Food Facts ships categories_tags on every product, and at first glance it looks hierarchical. It isn’t: those tags are the flattened union of every ancestor category drawn from the Open Food Facts category taxonomy, which is a directed acyclic graph where a single category can have several parents. Joining the tags with / mixes parallel roots and sibling branches and produces a path that doesn’t exist.
To get a real tree, the extractor loads the public Open Food Facts category taxonomy (the parent/child graph) and, for each product, walks a single canonical chain: it keeps the product’s taxonomy-known tags, induces the subgraph of just that product’s categories, picks the most specific leaf, and walks parents upward along the longest path to a root. The result is emitted as category_path — an array of cumulative /-joined strings:
raw tags: en:plant-based-foods-and-beverages, en:beverages, en:hot-beverages,
en:plant-based-beverages, en:teas, en:tea-bags (a flat DAG union)
category_path:
[ "Beverages",
"Beverages/Hot beverages",
"Beverages/Hot beverages/Teas" ] (one clean chain)
This is the same cumulative-path shape that merchandising tools expect for breadcrumb navigation and drill-down category facets, and the display names are taken from the taxonomy, so non-English personas get localized category labels. The original flat categories list is still emitted alongside it.
Benefits
The key is that once the data is in this shape, you can iterate on search logic quickly. Query rewriting rules, category routing, facet behavior, synonyms, typo handling, attribute extraction — all of it becomes easier when the data is already clean.
How the data looks
Below is an example of how the cleaned Open Food Facts data looks in a simple e-commerce frontend.
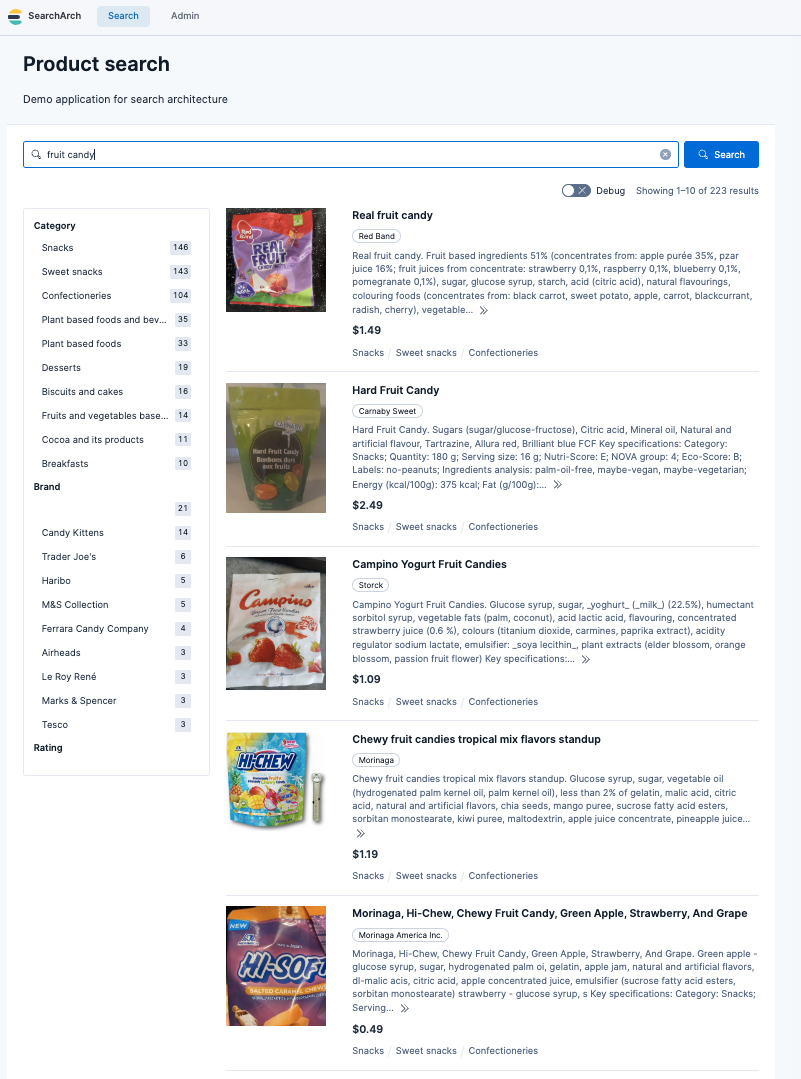
Dataset #2: Icecat for electronics-style product catalogs
Open Food Facts is excellent for food/CPG. But some demos benefit from an electronics-style catalog with spec-rich attributes and product-type variety. That’s where Icecat is useful.
Icecat is typically consumed via XML interfaces and nested structures that cannot be indexed directly into Elasticsearch. The Icecat harvester repo is designed as data transformation tool, where downloading and parsing are separate steps. That separation matters: you can download once, iterate on schema transformation many times, and regenerate clean NDJSON without re-downloading everything.
Icecat inclusion criteria (why 25M → 3.5M → 1M)
The raw Icecat index spans more than 25 million data sheets in the global catalog. However, I have targeted a subset of the open index covering only “interesting” categories of products (the desired categories are easily configurable). This subset contains approximately 3.5M data sheets. After further filtering and processing, I end up with about 1M demo-quality products.
The final resulting demo dataset is significantly smaller than the original 25M for the following reasons:
Open vs. full tier: We specifically target the “Open Icecat” portion of the catalog. While the “Full Icecat” database includes over 28,000 brands, only a subset (the “sponsoring brands” like HP, Lenovo, and Samsung) make their content available via the Open Icecat tier.
Regional/category filtering: We use a targets.txt file to focus only on high-utility categories (like Laptops and Smartphones). This avoids millions of low-signal categories (e.g., spare parts, cables) that typically clutter a demo search experience.
The demo-ready quality gate: Our script applies a strict filter: No Image = No Entry. A product without a visual asset is a dead-end in a demo UI. By requiring at least one high-resolution image URL and a valid title, we prune the “metadata-only” records that make up a large portion of the raw feed.
Deduplication: Icecat often provides separate XML files for the same product to handle different languages or minor regional packaging variants. Our pipeline deduplicates these by Product ID, ensuring that the search index contains one canonical record per item rather than many near-identical variants.
After: Cleaned NDJSON for electronics search
After parsing, filtering, and cleaning over 3.5 million source records, the resulting dataset contains over a million clean JSON objects, that are ready to be indexed into a search engine like Elasticsearch or OpenSearch.
{
"id": "91778569",
"title": "Lenovo Legion 5 15ARH05H AMD Ryzen™ 7 4800H Laptop...",
"brand": "Lenovo",
"description": "Minimal meets mighty... Thermally tuned via Legion Coldfront 2.0.",
"price": 865.33,
"currency": "EUR",
"image_url": "https://images.icecat.biz/img/gallery_mediums/79117985_5269963235.jpg",
"categories": ["Laptops"],
"attrs": {
"Processor family": "AMD Ryzen™ 7",
"Internal memory": "16 GB",
"Weight": "2.46 kg"
},
"attr_keys": ["Processor family", "Internal memory", "Weight"]
}
How the data looks
Below is an example of how the cleaned icecat data looks in a simple e-commerce frontend.
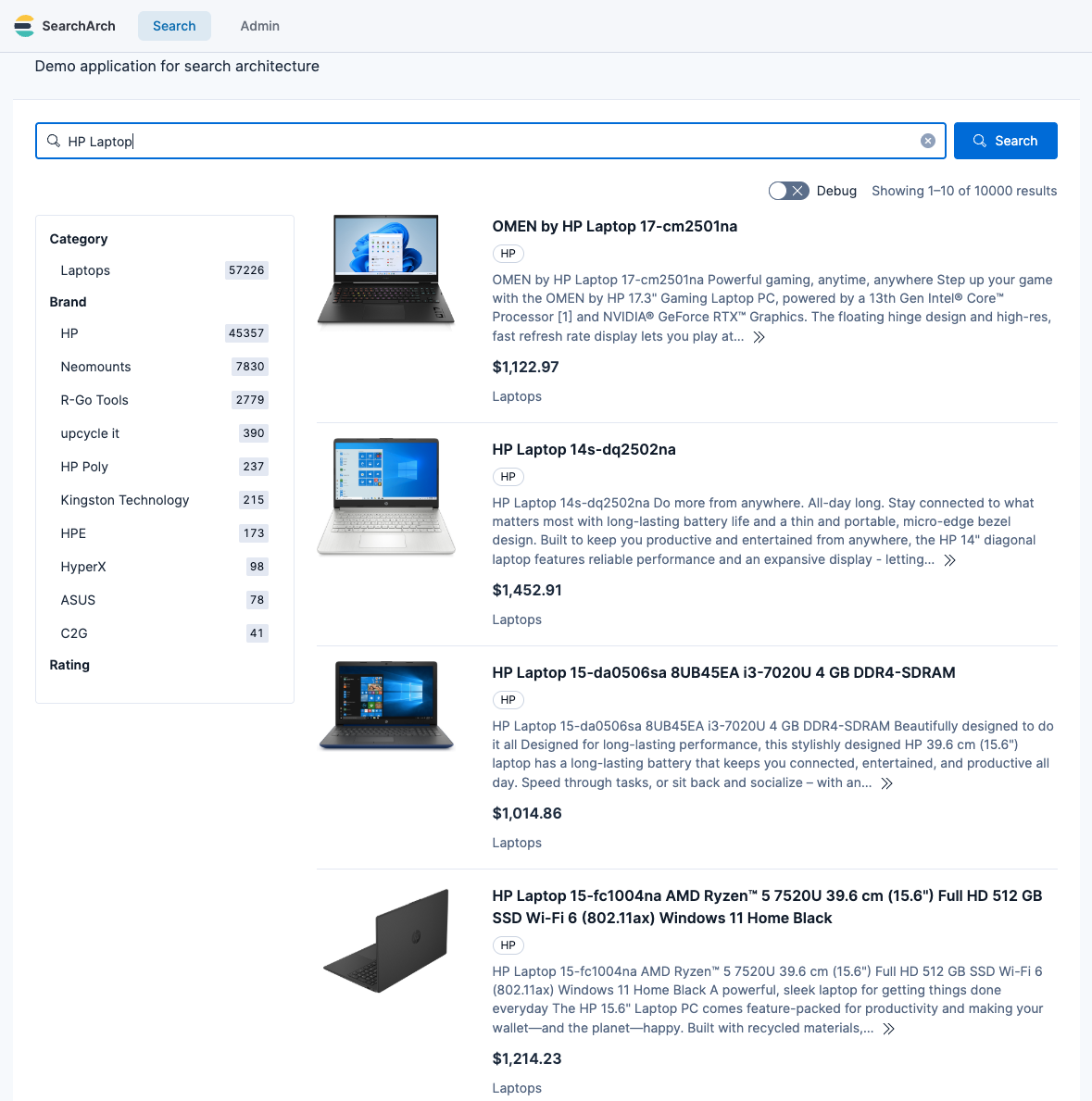
One schema, two sources
The goal is that a loader or indexing pipeline can ingest both Icecat and Open Food Facts with the same code path. That’s why both repositories converge on a similar NDJSON structure:
| Field | Type | Source: Icecat Logic (Electronics) | Source: Open Food Facts Logic (Grocery) |
|---|---|---|---|
| id | string | Unique Icecat Product ID | Padded GTIN-13 Barcode |
| title | string | Full Marketing Title | English Product Name |
| brand | string | Manufacturer (e.g., Apple, Lenovo) | Brand/Producer Name |
| description | string | Synthesis: Marketing text + Key Technical Specifications | Synthesis: Ingredients + Key Nutritional Metadata |
| price | float | Heuristic: Category baseline modified by Brand premium | Estimated: Unit pricing model based on category & weight |
| currency | string | Fixed (EUR) | Fixed (USD by default; set in config/pricing_buckets.json) |
| image_url | string | High-Quality: Selects the best available primary product photo | Computed: URL derived from product code and image metadata |
| categories | list | Single-item list (Primary Icecat Category) | Flat list of category labels (broad to specific) |
| category_path | list | Not populated | Hierarchical: single root→leaf chain as cumulative /-joined strings, rebuilt from the OFF category taxonomy graph |
| attrs | object | Flattened: Technical specs (e.g., "RAM": "16GB") | Flattened: Nutritional/Labels (e.g., "Nutri-Score": "A") |
| attr_keys | list | List of keys in attrs for dynamic faceting | List of keys in attrs for dynamic faceting |
Why this schema works for search
By converging on a single schema contract, the ingestion pipeline and demo UI can remain stable across both datasets. Whether you are indexing 100K olive oils or 1M laptops, the same configuration applies:
Consistent faceting: The attrs object is a flat dictionary. In Elasticsearch, this is typically mapped as a
flattenedfield to support dynamic faceting without a mapping explosion.Searchable specs: High-value technical data is injected into the description field. This ensures that a user searching for “Ryzen 7” or “Palm-oil free” finds the product via full-text search even if those specific attributes aren’t explicitly boosted.
Visual reliability: Both pipelines discard any record missing a valid image_url. This reduces the chances of your demo showing a “broken image” icon.
Where WANDS fits: evaluation, not demos
It’s worth calling out one dataset that I do consider extremely valuable: WANDS (Wayfair ANnotation Dataset).
WANDS includes query-product relevance judgments. That makes it excellent for benchmarking relevance changes and checking whether something you did actually improved ranking quality. The dataset is also explicitly MIT licensed.
- WANDS repo: https://github.com/wayfair/WANDS
- Paper: https://easychair.org/publications/preprint/j2D4/download
However, WANDS is comparatively small, and it is not ideal as a primary “demo catalog.” The biggest practical issue for demos is that a demo UI benefits enormously from images, and WANDS is not structured as an image-forward catalog. For my purposes, WANDS is something I want in the toolbox for evaluation, while the demo catalog comes from OFF and Icecat.
In other words: WANDS allows you to quantitatively evaluate quality of search results, while Open Food Facts/Icecat data allows you to create realistic demos and to evaluate results qualitatively.
Other datasets we considered (and why we did not choose them)
There are many attractive datasets in the research ecosystem, but many of them come with constraints that make them awkward for customer-facing demos or reusable internal assets.
Amazon-derived datasets (UCSD / McAuley Lab)
The UCSD / McAuley Lab Amazon datasets are impressive: reviews, metadata, sometimes images, large scale. For demos, they look great on paper.
The problem is not technical quality. The problem is posture: the underlying content originates from Amazon, and many releases are framed as academic research resources. In addition, the Amazon Reviews 2023 ecosystem is frequently referenced with non-commercial research restrictions in some derivative distributions.
- Amazon Reviews 2023 landing page: https://amazon-reviews-2023.github.io/
- UCSD Amazon review data: https://jmcauley.ucsd.edu/data/amazon/
- Example derivative noting “Academic, non-commercial research use only”: https://huggingface.co/datasets/bagadbilla/amazon-reviews-2023-trimmed
If you are building a reusable demo asset, there may be legal obstacles to using this data.
SIGIR eCom / Coveo data challenge datasets
These datasets are excellent for research, especially session-based behavior (queries, clicks, add-to-cart, etc.). They are also often explicitly described as being made available for research purposes, with access gated by terms.
- SIGIR eCom 2021 / Coveo challenge repo: https://github.com/coveooss/SIGIR-ecom-data-challenge
If you’re doing academic work or internal R&D, they can be great. If you’re building a demo catalog that you want to use broadly in customer conversations, the terms can complicate things.
Kaggle competition datasets (H&M example)
Kaggle competitions are a common source of “easy to download” datasets that look demo-friendly. The issue is that many competitions explicitly restrict use to non-commercial purposes.
- H&M competition rules (non-commercial clause): https://www.kaggle.com/competitions/h-and-m-personalized-fashion-recommendations/rules
Again: excellent for learning, but not the cleanest foundation for customer-facing demos.
TREC Product Search and “Amazon thumbnail” corpora
Some product search datasets include images and evaluation infrastructure, but the provenance matters. For example, the TREC 2023 Product Search track overview explicitly discusses product images extracted from Amazon thumbnails and joined using ASINs.
- TREC 2023 Product Search overview: https://arxiv.org/pdf/2311.07861
This may be perfectly fine for research benchmarking, but it reintroduces the same “marketplace-derived content” concern when you want a demo catalog with a clean commercial posture.
Conclusion
If you want to build and demo e-commerce search, the blocker is often the dataset.Open Food Facts and Icecat are two sources that (a) contain the kinds of fields demos need, including images and metadata, and (b) have licensing frameworks that are clear enough to build on without feeling like you’re stepping into a gray area. The real work — and the real value — is in turning raw, awkward source formats into clean, stable NDJSON that is easy to index, easy to query, and easy to use in demos. Not more, not less.
If you’re doing relevance evaluation, WANDS is still in the picture. It’s a different tool for a different job. But for demo catalogs that look and feel real, Icecat and Open Food Facts are the two foundations I’m using today.